#CSS渲染
css是从右向左解析的
一开始我看到这个从右向左解析渲染的时候,也是呆了一下,但是想想这确实是目前效率最高的方式了。
OK,开始。
浏览器架构
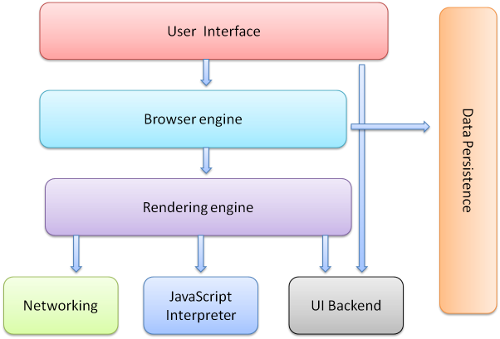
1.用户界面 - 用户使用的界面:地址栏,书签,前进后退等
2.浏览器引擎 - 在用户界面和渲染引擎之间传递指令
3.渲染引擎 - 负责显示请求的内容,解析一些HTML、CSS并显示到屏幕
4.网络层 - 网络调用,比如:http、websocket等
5.JavaScript解释器 - 用于解释执行JavaScript代码
6.用户界面后端 -
7.数据存储 - 浏览器需要将持久化的数据存储在硬盘上。不如Cookie、localstroge等
我主要讨论一下渲染引擎
渲染引擎
渲染引擎从网络层获取到请求问道的内容之后,就会执行如下基本流程:
1.渲染引擎开始解析HTML文档,并将各个标记逐渐转化成DOM树上的DOM节点。同时,解析外部CSS文件以及样式元素中的样式数据。等所有CSS文件获取成功后,结合内部style和行内样式,生成render树,render树包含了每个DOM的节点的样式信息。
2.结合DOM树和render树来绘制页面。
CSS是从右向左解析的
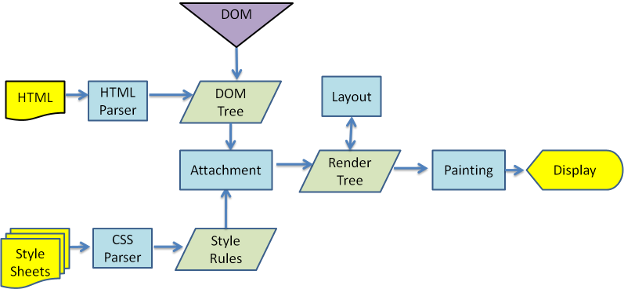
构建render树的过程是遍历dom树,每次拿到一个dom节点,然后遍历所有的样式规则,查找与当前节点匹配的规则,最后将所有匹配的规则中定义的样式写入到一个render对象,再将render对象挂到render树上(建立对象和render树的联系)。如图:
也就是说,每一个dom,已知的是class,id和tabName
<a id="aa" class="bb" href="">,但是匹配的规则可能有成千上万条,渲染引擎需要从中找到符合条件的1条或者多条(数量不会很多)。由于每条规则都有很多嵌套例如:
#content .box p{} .title a{}假如采用从左向右的方式读取CSS规则,那么大多数的规则读取到后面发现是不匹配的,会浪费很多时间在无用的匹配上。
所以,采用从右向左匹配就会在发现最后边或者次右边的选择器不匹配,整个规则就可以跳过了。
在css模块化了之后,模块打包到一个css文件中了。 比如:
1 | .model_a a |
浏览器会遍历所有的a,所以加大了匹配时间,所以,提倡不用tag标签来定义样式,一律用类 .class